HTTP请求走私
这是一些关于HTTP请求走私的一些学习笔记和总结,也有一些借鉴,Copy啦!QwQ~====
浅谈HTTP请求走私
--------------TWe1v3
本文主要针对HTTP/1.1协议的请求走私做一些讲解,不涉及HTTP/2.0、HTTP/3.0的相关技术。不过这里可以说一下HTTP和HTTPS的一些差别:
HTTP与HTTPS不同
- HTTPS需要CA(Certificate Authority,数字证书认证机构) 申请证书,免费的很少
- HTTP默认80端口;HTTPS默认443端口
- HTTP使用http标识符;HTTPS使用https标识符
- HTTP是明文传输;HTTPS是加密传输
- HTTP响应比HTTPS快,因为HTTPS还需要TSL握手,所以HTTPS更耗费服务器资源
产生原因
当今的 Web 应用程序经常在用户和最终应用程序逻辑之间采用 HTTP 服务器链。用户将请求发送到 前端服务器(有时称为负载平衡器或反向代理),此服务器将请求转发到一个或多个后端服务器。 这种类型的架构在现代基于云的应用程序中越来越普遍,在某些情况下是不可避免的。
当前端服务器将 HTTP 请求转发到后端服务器时,它通常会通过同一后端网络发送多个请求 连接,因为这更加高效和高性能。协议非常简单:HTTP请求一个接一个地发送,并且 接收服务器解析 HTTP 请求标头,以确定一个请求的结束位置和下一个请求的开始位置:
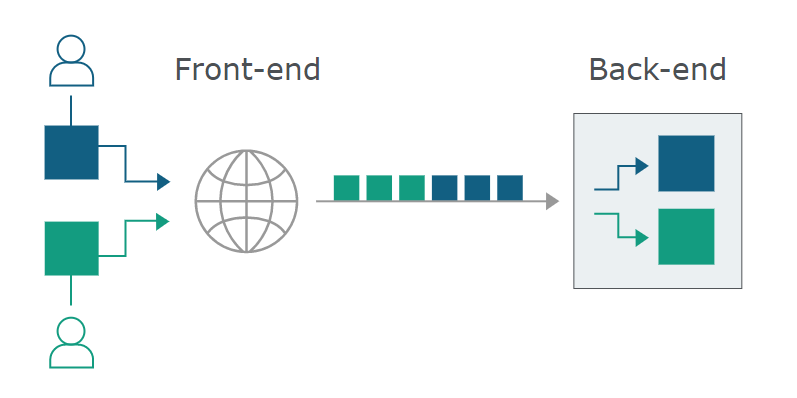
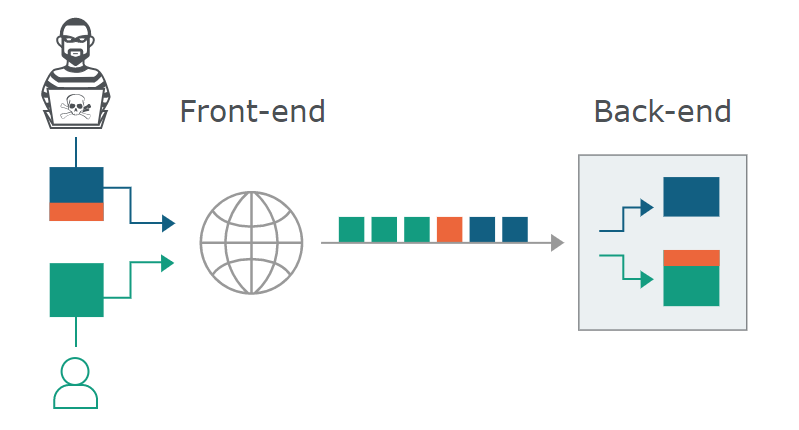
原因:当网站使用两个服务器(一个前端,一个后端)来处理用户所提交的数据,而两个服务器之间对HTTP header的处理不一致,就可能产生HTTP走私问题。
现在的Web应用程序经常在用户和最终的应用程序之间使用HTTP服务器链。用户将请求发送到前端服务器(有时称为负载平衡器或反向代理,也可能是WAF),并且该服务器将请求转发到一个或多个后端服务器。
前置知识
HTTP/1.1的特性
Keep-Alive
Keep-Alive(又称持久连接),在HTTP/1.1中,默认使用启用Keep-Alive,Keep-Alive功能使客户端到服务器端的连接持续有效,同一对客户/服务器之间的后续请求和响应可以通过这个连接发送。
支持pipeline
HTTP/1.1允许在持久连接上可选地使用请求管道(意味pipeline是依赖于持久连接的,而不是独立的)。pipeline请求管道可以在响应到达之前,将多条请求放入队列,但对于pipeline的请求顺序和响应顺序是相对应的。

对于Keep-Alive模式,如何判断请求所得到的响应数据已经接收完成
Conent-Length
Conent-Length表示实体内容长度,当客户端向服务器请求一个静态页面或者一张图片时,服务器可以很清楚的知道内容大小,然后通过Content-length消息首部字段告诉客户端 需要接收多少数据。
Transfer-Encoding
分块编码,数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。
分块编码(Transfer-Encoding: chunked)
- 在头部加入 Transfer-Encoding: chunked 之后,就代表这个报文采用了分块编码。这时,报文中的实体需要改为用一系列分块来传输。
- 每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(\r\n),也不包括分块数据结尾的 CRLF(\r\n)。
- 最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
例:
1 | HTTP/1.1 200 OK |
几种走私类型
CL-TE
前端服务器使用Content-Length头,而后端服务器使用Transfer-Encoding头。
发送两次请求,当第二次请求时出现HTTP方式错误,则存在走私问题。实验截图:
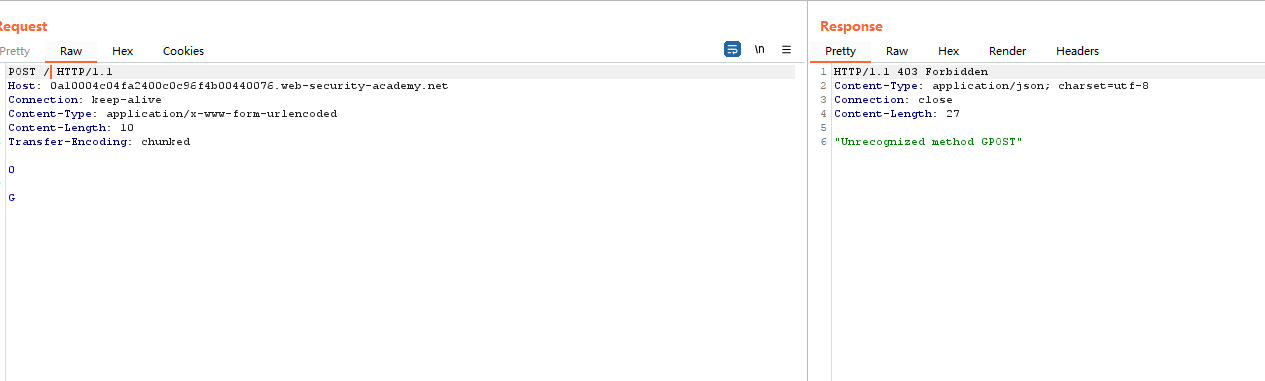
原因就是第一次前端服务器解析时,使用Content-Length头判断结束,所以传给后端服务器的数据为
1 | 0\r\n |
总共加起来为6,而后端服务器以 Transfer-Encoding: chunked 判断结束,当遇到
1 | 0\r\n |
在分块传输中,则代表结束,而后面的 G ,服务器判断未完成的请求,将遗留在缓存中,所以当第二次请求时,接在了 G 的后面,如下:
1 | GPOST / HTTP/1.1 |
这就完成了一次成功的请求走私
在实际情况中是不会出现HTTP请求方式错误的,可以通过时间延迟来判断是否存在CL-TE类型的走私问题:
1 | POST / |
如果存在走私问题,下一个请求就会有明显的延迟。

或者使用下面的payload进行验证,如果存在走私问题,则会返回错误的页面:
1 | POST /search |

- 注意
由于前端服务器处理Content-Length,需要把我们所有的内容都发送到后端服务器中去,那这个Content-Length可以用Brupsuite自动计算。
TE-CL
前端服务器使用Transfer-Encoding头,而后端服务器使用Content-Length头。
简单判断payload
1 | POST / |
时间延迟payload
1 | POST / |
响应差异payload
1 | POST / |
- 注意
需要注意的是走私的请求中,Content-Length一定要少于后面请求中的长度,否则后台会Timeout出现错误。
TE-TE
前端服务器和后端服务器都支持Transfer-Encoding标头,但是可以通过以某种方式混淆标头来诱导其中一台服务器不对其进行处理。
混淆的方式:
1 | Transfer-Encoding: xchunked |
简单判断payload
1 | POST / |

利用HTTP请求走私漏洞
Bypass前端服务器安全验证
场景:前端服务器对某些页面添加了访问限制,比如实验中对admin页面控制在只能是后端服务器才能访问,此时可以通过HTTP走私漏洞来绕过这个限制。
- CL-TE
发送两次请求,响应消息反馈不允许重复header

于是,加个传输字符数限制,将走私后面的请求去掉,即可访问/admin界面了


完成删除用户

- TE-CL


获取前端服务器对请求的重写情况
场景:前端服务器通常在请求添加到其他请求头之前,先对请求进行一些重写,然后再转发给后端服务器。一般是添加一些HTTP HEADER。可以通过HTTP走私请求来获取到这些重写内容。
但走私的前提需具备一些条件:
- 存在一个POST请求,传入参数会储存并可以被查看
- 存在HTTP走私请求
构造一个chunk,包含一个完整的post请求,把可以储存的参数放在最后。当第二个请求传递时,则会把HTTP HEADER添加在参数后面而被存储。就可以获取到前端服务器所添加的HTTP HEADER。这里需要注意Content-Length不能超过所传递数据包的长度,不然会导致请求失败
尝试走私请求直接访问/admin,却返回响应信息只有管理员登陆或者从127.0.0.1请求才可以访问

页面上有个搜索框,输入任意内容,会在页面上返回出来


于是利用这个搜索参数,将前端服务器重写请求的情况展示出来,发现了 X-trnzSu-Ip 请求头

于是加入走私的请求,再尝试访问/admin发现成功


获取其他用户的cookie
参考上一个实验,这个实验也是通过获取HTTP HEADER来获取其他用户的Cookie。

HTTP header导致的XSS
场景:通常情况下,HTTP HEADER导致的XSS是不好利用的,但是通过HTTP走私请求,我们能够控制HTTP HEADER,进而就可以利用这类HTTP头导致的XSS。


将重定向转变为任意重定向
场景:许多应用程序执行现场重定向,并将主机名从请求的Host标头放入重定向URL。
示例:
1 | GET /home |
通常,此行为被认为是无害的,但是可以在走私请求攻击中利用它来将其他用户重定向到外部域。例如:
1 | POST / |
走私的请求将触发重定向到攻击者的网站,这将影响后端服务器处理的下一个用户的请求。例如:
1 | GET /home |
缓存投毒
- 构造一个页面中写入恶意的内容,比如写入alert(document.cookie)
- 发送请求走私的内容
1 | POST / |
- 再寻找到一个可用缓存的js页面(可用导致xss的js)访问。页面会跳转到恶意页面中,并且将恶意内容缓存到服务器上。
- 打开主页 ⇒ 导致xss
缓存欺骗
缓存欺骗:在Web缓存欺骗中,攻击者使应用程序将一些属于另一个用户的敏感内容存储在缓存中,然后攻击者从缓存中检索此内容。
- 寻找一个存在隐私的页面,比如这里的my-account,并且页面返回的内容是可以被缓存的
- 发送一个走私请求,下一个请求静态资源的请求会跳转到my-acount并把隐私信息缓存
1 | POST / |
- 打开隐私浏览器加载主页,用Brupsuite搜索隐私内容的关键字。如果成功的话可以在静态资源中搜索到

原理是走私的请求把下一个请求HTTP方法那一行注释,请求会变为:
1 | GET /private/messages HTTP/1.1 |